我們在 上上一篇 也有提到過 slate 將 Normalizing 這項功能的實現拆成了第一步驟的『骯髒標記( Dirty-Path ) 』以及透過骯髒標記實際實行『正規化( Normalize )』的第二步驟。
順序都分出來了我們當然先來看一下骯髒標記到底是哪裡被弄髒了。
首先我們在 weak-map.ts 裡可以看到一組名叫 DIRTY_PATHS 的 WeakMap
// weak-map.ts
export const DIRTY_PATHS: WeakMap<Editor, Path[]> = new WeakMap()
它負責紀錄編輯器當前的骯髒路徑內容,供後續的 methods 使用。
如果讀者還記得我們在 Day21 貼的 apply method 的 code 的內容的話就會發現其中設定 Dirty-Paths 的 section 裡又拆成了 oldDirtyPaths 與 newDirtyPaths 兩個變數,並針對這兩組變數額外進行一些處理後才整合進 DIRTY_PATHS 裡。
這麼做是因為 Normalize 的執行方式並不是『一個 Operation 搭配一次 Normalize 』,而是『一組完整的 FLUSHING 搭配一次 Normalize 』,想想看一次 Transform 裡有好多次的 Operations ,真要是這樣實作的話該有多耗效能啊!才剛弄乾淨馬上就又被弄髒了
而不同的 Operation 有機會生成不同的骯髒路徑,也因此 slate 需要這項機制為它整理出一組 FLUSHING 裡最後確定需要 Normalize 的 Dirty Paths ,一樣來看看它是怎麼運作的:
const set = new Set()
const dirtyPaths: Path[] = []
const add = (path: Path | null) => {
if (path) {
const key = path.join(',')
if (!set.has(key)) {
set.add(key)
dirtyPaths.push(path)
}
}
}
const oldDirtyPaths = DIRTY_PATHS.get(editor) || []
const newDirtyPaths = getDirtyPaths(op)
for (const path of oldDirtyPaths) {
const newPath = Path.transform(path, op)
add(newPath)
}
for (const path of newDirtyPaths) {
add(path)
}
DIRTY_PATHS.set(editor, dirtyPaths)
在每一次的 Operation 中:
oldDirtyPaths 會去取得儲存在 DIRTY_PATHS 裡頭前一次的結果,經過這次的 operation transform 為正確的 path 以後經由 add method 推入 dirtyPaths 變數裡。newDirtyPaths 會透過 getDirtyPaths 取得這次 operation 會製造出的 Dirty-Path 並經由 add method 推入 dirtyPaths 變數裡。add method 會將丟入的 path 與第一行的 set 比對,只推入還不存在於 dirtyPaths 變數裡的 path 以避免重複推入。dirtyPaths 存為 DIRTY_PATHS 裡 editor 的 value 。與 Dirty-Path 生成相關的一切邏輯都被封裝在 getDirtyPaths 這個 helper function 裡。
除了 SetSelectionOperation 與 SetNodeOperation 之外,其他 Operations 都會生成 Dirty-Path 。
const getDirtyPaths = (op: Operation): Path[] => {
switch (op.type) {
case 'insert_text': ... // Implementation
case 'remove_text': ... // Implementation
case 'set_node': ... // Implementation
case 'insert_node': ... // Implementation
case 'merge_node': ... // Implementation
case 'move_node': ... // Implementation
case 'remove_node': ... // Implementation
case 'split_node': ... // Implementation
default: {
return []
}
}
}
一個一個來看他們的判斷標記的概念吧:
insert_text 、 remove_text 、 set_node
這三組 Operations 會標記的骯髒路徑一樣都是『一路從根節點串連下來的祖先路徑與 op.path 本身的路徑』:
case 'insert_text':
case 'remove_text':
case 'set_node': {
const { path } = op
/**
Path.levels: Get a list of paths at every level down to a path. Note: this
is the same as `Path.ancestors`, but including the path itself.
*/
return Path.levels(path)
}
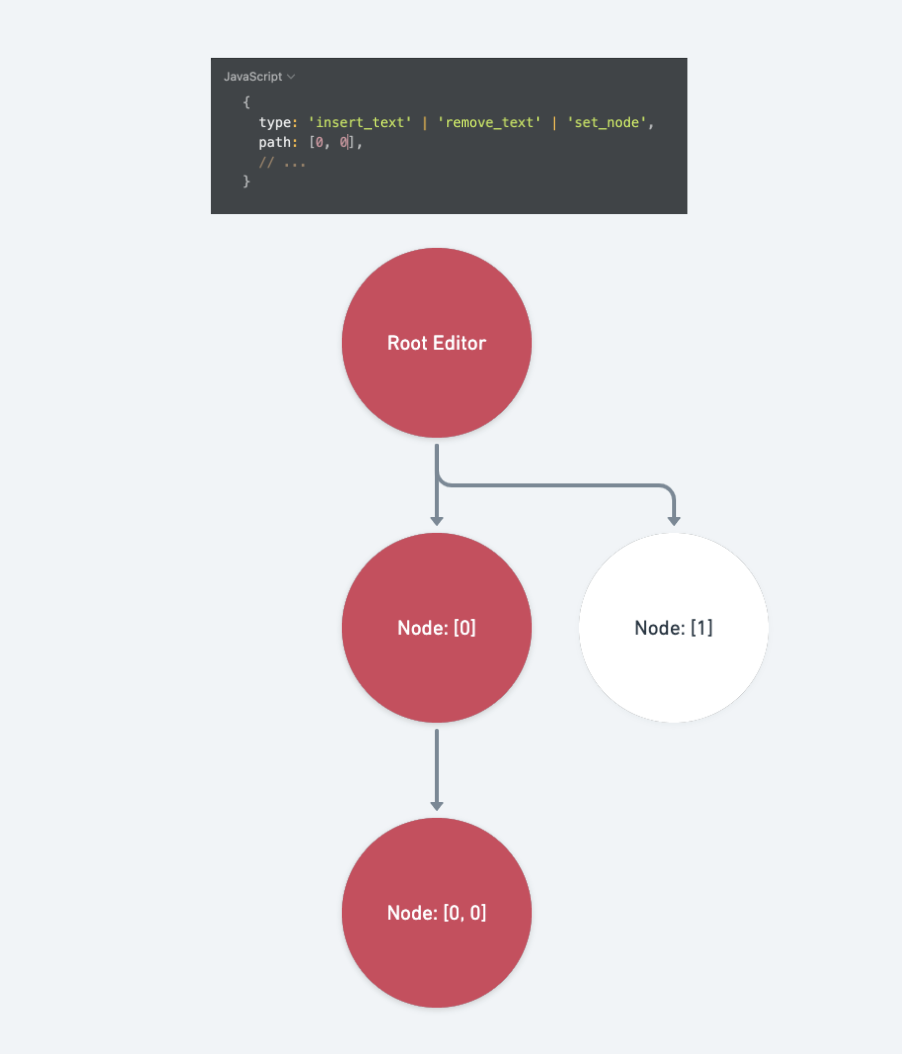
insert_node
受到骯髒標記的路徑包含: op.path 的祖先路徑、 path 本身、 path 的子層路徑:
case 'insert_node': {
const { node, path } = op
const levels = Path.levels(path)
const descendants = Text.isText(node)
? []
: Array.from(Node.nodes(node), ([, p]) => path.concat(p))
return [...levels, ...descendants]
}
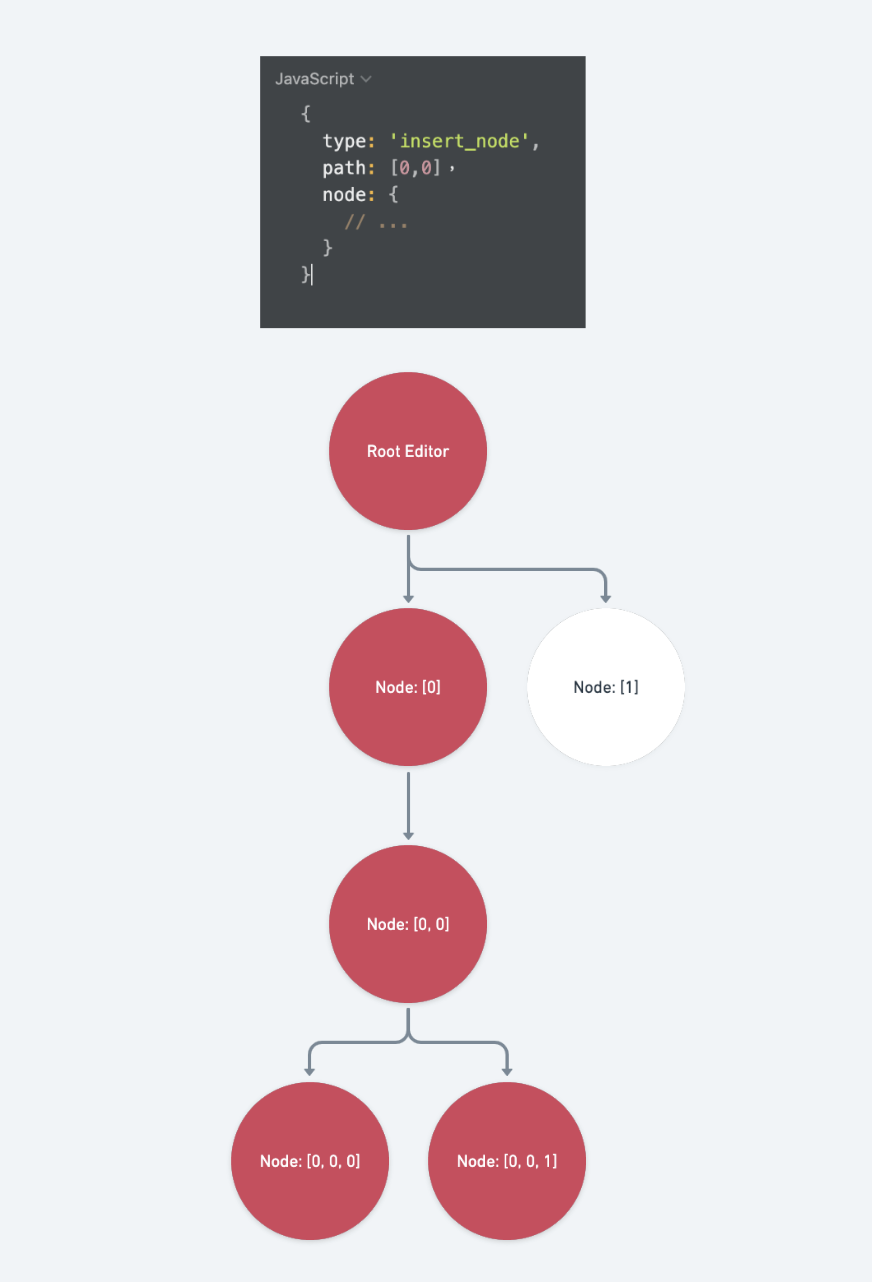
merge_node
受到骯髒標記的路徑包含: op.path 的祖先路徑、 path 同層的前一個 sibling (因為是向前合併,所以只需要標記前一個 sibling 而不需要標記 path 本身)
case 'merge_node': {
const { path } = op
const ancestors = Path.ancestors(path)
const previousPath = Path.previous(path)
return [...ancestors, previousPath]
}
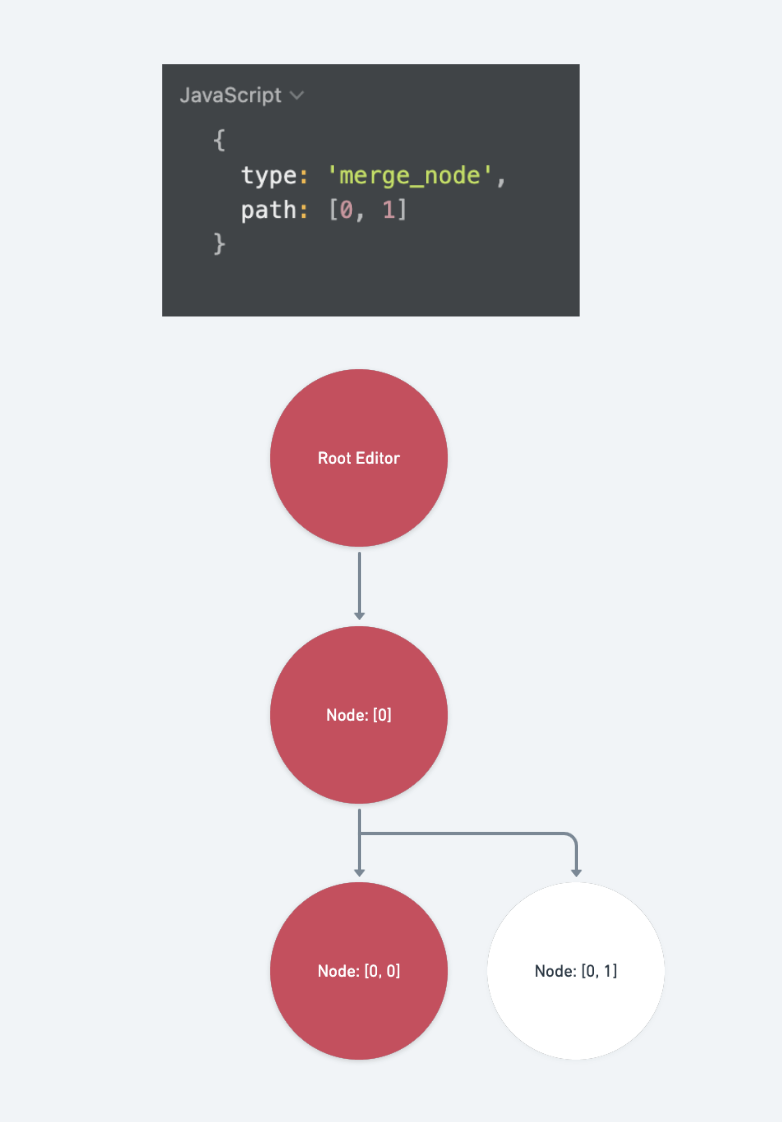
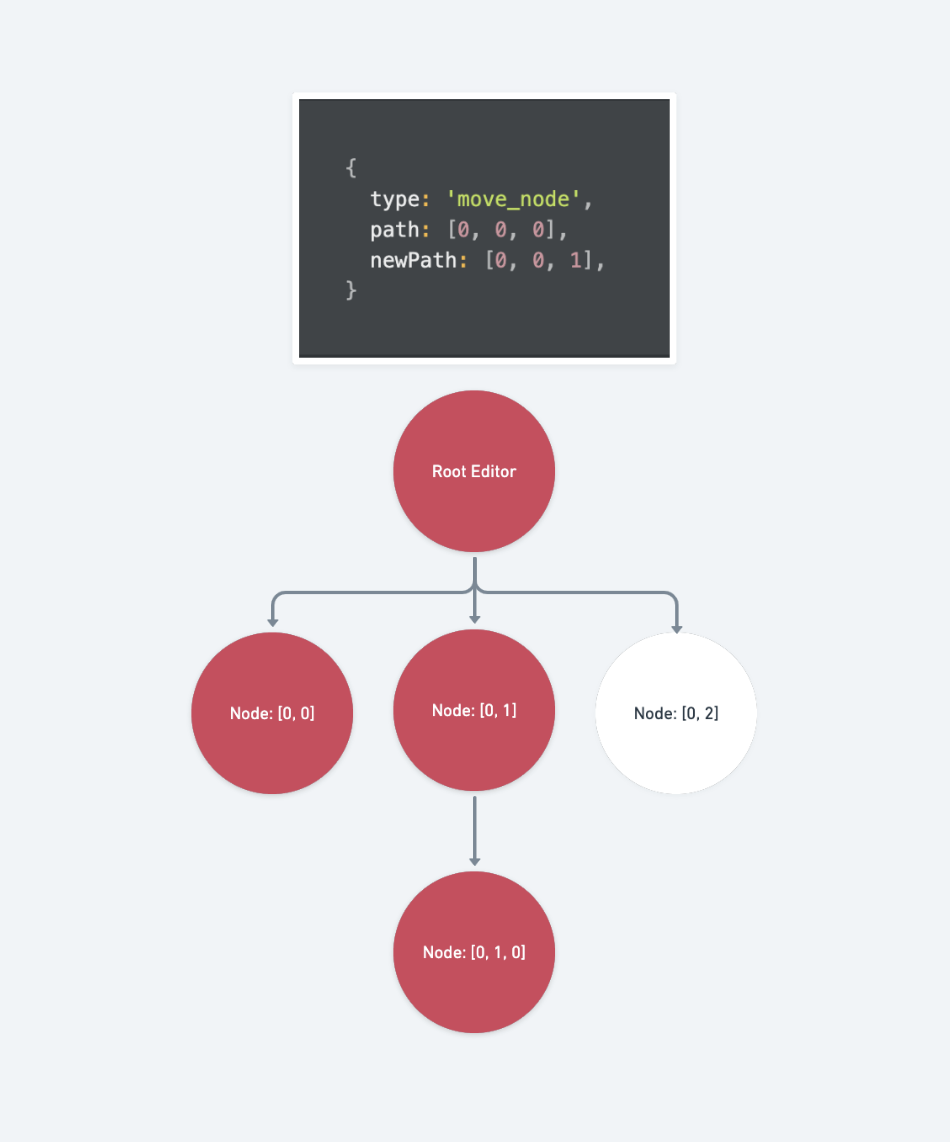
move_node
受到骯髒標記的路徑包含:
欲移動路徑經由 Path.transform 更新過後的所有祖先路徑
const oldAncestors: Path[] = []
for (const ancestor of Path.ancestors(path)) {
const p = Path.transform(ancestor, op)
oldAncestors.push(p!)
}
移動到的目標路徑經由 Path.transform 更新過後的所有祖先路徑
const newAncestors: Path[] = []
for (const ancestor of Path.ancestors(newPath)) {
const p = Path.transform(ancestor, op)
newAncestors.push(p!)
}
最後是移動結果的路徑
const newParent = newAncestors[newAncestors.length - 1]
const newIndex = newPath[newPath.length - 1]
const resultPath = newParent.concat(newIndex)
將上述三組路徑們包成一組陣列回傳回去
return [...oldAncestors, ...newAncestors, resultPath]
remove_node
受到骯髒標記的路徑為被移除之路徑的祖先路徑
case 'remove_node': {
const { path } = op
const ancestors = Path.ancestors(path)
return [...ancestors]
}
split_node
受到骯髒標記的路徑包含: op.path 的祖先路徑、 path 本身、與 path 同層的後一個 sibling
case 'split_node': {
const { path } = op
const levels = Path.levels(path)
const nextPath = Path.next(path)
return [...levels, nextPath]
}
明天就到了本章節的最後一篇了,介紹完第一步驟的骯髒標記以後當然就輪到了實際執行正規化的第二步驟了。
要介紹的內容其實也算是整個 slate 裡數一數二複雜的,為了因應正規化所會遭遇到的問題以及整體的設計與效能上的考量,作者將第二步驟拆成了好幾層 function 彼此各司其職,當初筆者在研究時也是在各個函式之間穿梭,上滑下滑滑到懷疑人生 ...
那麼今天的文章就到這邊為止,咱們明天再見囉~

